
Intro to Uno Orchestrator
Lusha Uno Orchestrator service is the Temporal-based workflow engine that coordinates long-running, multi-step data population jobs for Lusha Uno (our new contacts and companies lists spreadsheet-like interface). It receives requests to fill Uno spreadsheet cells and delegates execution to durable Temporal workflows, which handle pagination of entities, capturing and charging credits, marking cells as pending, fetching data via child workflows (from services such as Lusha signals, AI, company or contact data), persisting results, and rolling back gracefully on failure - all reliably and asynchronously, decoupled from the original request.
The technical difficulties begin when you attempt to wrap these services with a Billing Service (for credit deduction) and a database (for final state persistence). Without a centralized engine, you inherit “spaghetti infrastructure”: a web of dispersed state machines, queues, manual retry logic, and database status flags. For example, if the AI service completes its run but the Billing Service is unreachable, or if the Postgres write fails after billing succeeds, the system enters an inconsistent state. The Uno Orchestrator utilizes the Saga pattern to ensure transactional integrity across these boundaries.
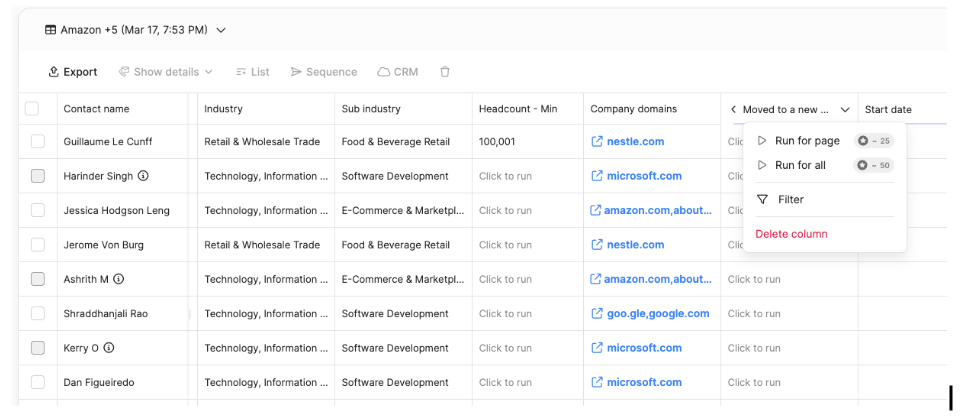
What we did in the beginning
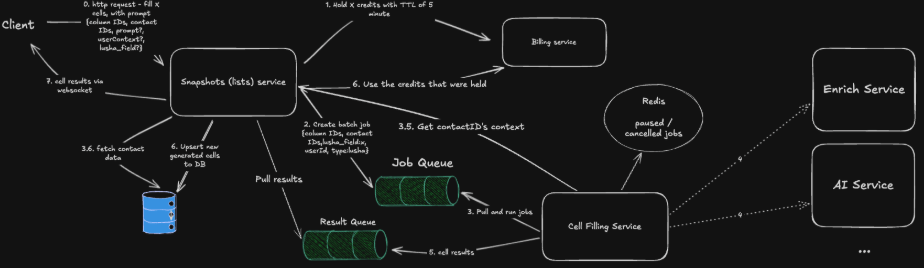
To put it briefly, when a client requests a cell or column fill, the Snapshots Service places a credit hold and pushes a batch job to a Job Queue, which the Cell Filling Service processes by fetching context and calling external AI/Enrich Services. Once tasks are complete, results flow through a Result Queue to be upserted into the database, triggering the final credit deduction and a real-time update to the Client via Websockets. This decoupled design ensures scalability and prevents data loss or overbilling if an external API call fails.
What wasn’t good enough and how temporal solves it
For the beginning of the project, what we did worked great - it was durable, the logs were clear, relevant alerts sent to a slack channel, retries were on point and integration with new services was easy but while we were vibing with our great state-of-the-art newly architected service, we foresaw that we’re heading towards big problems in the future.

How do we maintain all the queues and their dead letter queues for every service?
Uno is expected at least for now to support and integrate to 8 services, if each service needs 4 queues (job queue, result queue, and dead letter queue for each of them) then it means we would need to support and maintain at least 32 queues!
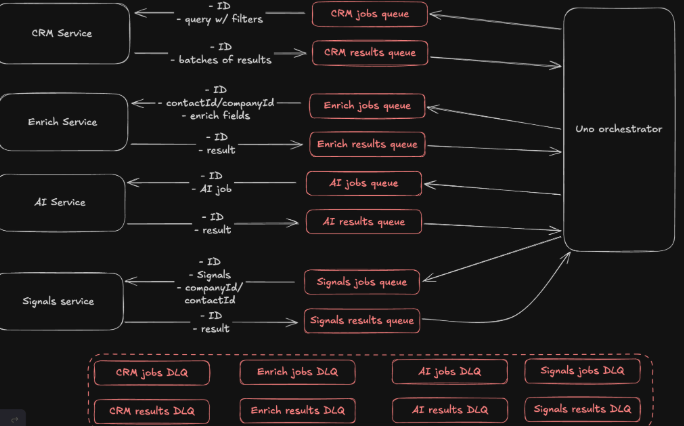
Temporal solves this by handling all the durability and retries for us automatically! Everything is set and managed by Temporal.
How do we cancel a job midway through?
Uno needs to support cancel/pause job run midway through a job. It is hard to implement because every service (especially the orchestrator) needs to implement a check (“is the current job cancelled?”) before every step, and this state must be consistent across the workflow. This is problematic because we need to manually implement a check before every step, both in Uno Orchestrator and every (!) service that is integrated with it, and store and manage every job’s state (running/cancelled/paused) ourselves.
We implemented the state management with a centralized Redis, but it is easy to see how this can go out of hand very quickly.
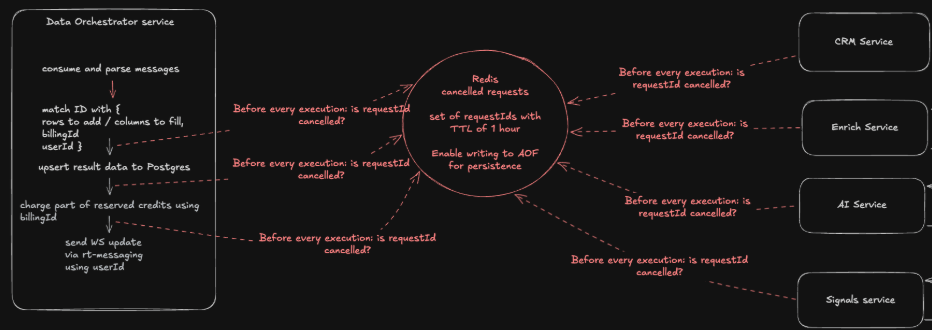
Temporal solves this by introducing signals. We (any microservice or the user) can send a signal cancel or pause signal to any running workflow and Temporal will handle the rest.
How do we revert and compensate when a failure or cancellation happens?
If a step fails (for example the billing step fails because user doesn’t have enough credits, or enrich fails because data-enrich service is down) after we started the flow, and retries are exceeded, we need to undo all the steps we did until now. In traditional architecture this will mean more queues, more logic, more bugs, worse observability and more mess.

Temporal solves this by ensuring transactional integrity by implementing the Saga pattern natively. When a step fails, Temporal's framework allows for the definition of compensatory actions that automatically execute to "undo" the completed steps, such as refunding a charged credit or deleting a partially written record, ensuring the system returns to a consistent state (for example, so no cells will be stuck on “pending” infinite loading state).
How do we know exactly where a failure happened and why?
In case of a user having a failure, we wanted to know exactly when, where and why it happened.
Sure, we can write comprehensive logs throughout the codebase at every step, including the external services, but that means huge code bloat with logs, spamming Coralogix and tough investigations across services when a user experiences an error we want to investigate.
Temporal solves this by keeping history of the input and output of every workflow and every activity (durable function).
The Case for Temporal
Choosing Temporal to back the Uno Orchestrator means treating the “state machine” as a first-class service. However, architects must acknowledge the compromises involved in this abstraction.
Pros
Code-First Orchestration: Define business logic in standard languages (Typescript in our case, but also supports Pythom, Go, Java…) rather than restrictive, non-testable JSON/YAML.
Durable Execution: State and local variables are preserved through system crashes, network partitions, or worker restarts. Upon worker failure or restart, the cluster sends the workflow’s Event History to a new worker. This worker deterministically replays the logic, to restore the exact prior state and resume execution seamlessly.
Built-in Retries: Native support for exponential backoff on external calls like Billing or Postgres, handled transparently by the cluster.
Observability: Every step of the workflow, from the initial request to a final state write, is tracked and logged (every activity’s input and output data object) to the Event History. This provides a complete, auditable trail for debugging, monitoring, and compliance.
External Signals: Signals represent an asynchronous communication pattern. They are external, non blocking messages sent from other microservices directly to a running Workflow Execution. Unlike a regular Workflow start or Activity call, a Signal does not initiate a new execution, its only purpose is to update the state, inject data, or convey an external event to an already active workflow instance. This allows for functionalities like pausing or cancelling a running workflow.
Cons
Latency: Because Temporal persists every event to the database to ensure durability, it is unsuitable for ultra-low latency (<100ms) requirements (it adds 10s to 100s of milliseconds overhead).
Determinism: Workflow logic must be deterministic. Non-deterministic code (for example Math.random() or our logging module) is fatal because Temporal uses Replay to reconstruct state from history, therefore it is not possible to use non-deterministic code.
Durable Execution in Practice
Consider the Uno AI service branch, which may take 48 hours to complete a complex model. In a traditional architecture, a server restart during this window would wipe the execution state. With Temporal’s Durable Execution, the orchestrator "waits" patiently; if the worker process dies, a new worker picks up the workflow, replays the event history to reconstruct local variables, and resumes exactly where it left off.
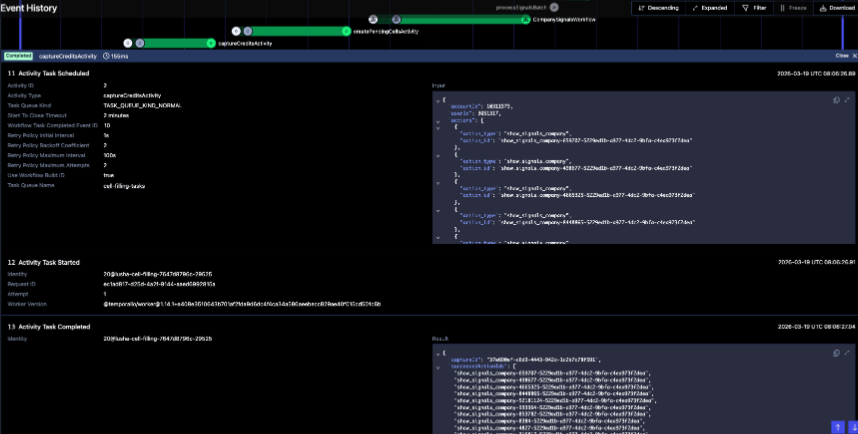
Event history timeline view:
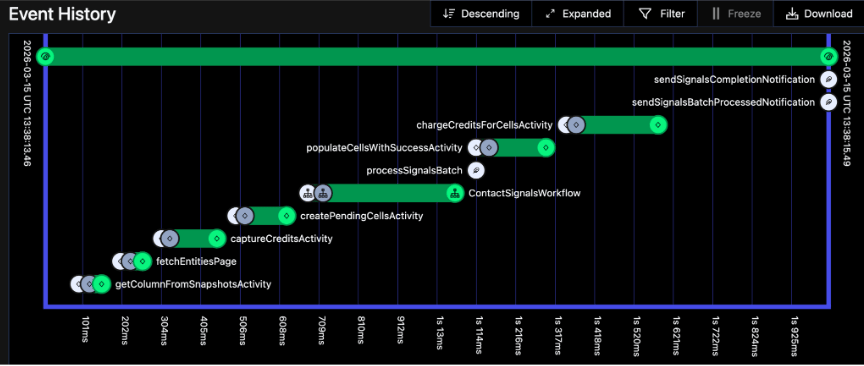
Workflow input, output and metadata view:
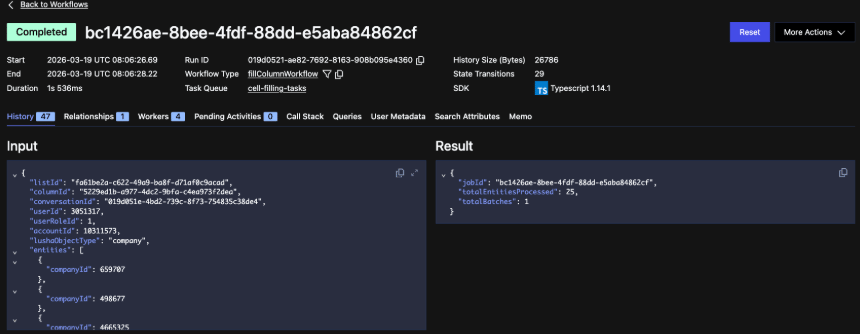
Specific activity input, output and metadata view:
Architecting Uno’s Hierarchy: Child Workflows
For the Uno Orchestrator, a monolithic workflow is a liability not only because of history bloat but also because every team owns its own service (CRM, Lusha Signals, AI, etc.). Instead, we utilize Child Workflows to encapsulate these branches. This modular hierarchy is essential for the Uno Orchestrator, a centralized service, to be able to trigger each team's workflow in a decoupled and modular way, and is also key to preventing history bloat, as each child maintains its own event log rather than stuffing thousands of events into the parent.
This allows us to have:
- Team-based Management: Different engineering teams can own and deploy the CRM or AI workflows independently.
- Isolated Worker Pools: Each service can run on its own Task Queue, allowing you to scale worker resources differently for every service
- Separate Event Histories: Breaking down logic ensures individual workflow runs remain lean and within performance limits.
Child Workflows are architecturally superior to simple HTTP calls for the "heavy lifting" in this system. While an HTTP call requires manual polling, a Child Workflow is a managed entity within the cluster, inheriting full visibility, native retries, and state tracking.
Activity Execution: Regular vs. Local Activities & Signals
In Temporal, we distinguish between activity types based on overhead and side-effects:
Activities:
- Regular Activities: Activities are like durable functions, used for external side-effects like calling the Billing Service or writing to Postgres. These are scheduled via the Matching Service and recorded in the event history. They are durable and have a “checkpoint” on start.
- Local Activities: These are executed within the same worker process as the Workflow parent, avoiding the full gRPC round-trip to Temporal’s Matching service and logging input and output to Temporal’s History service. They are ideal for short-lived, idempotent logic with low overhead. They are not durable and do not have a “checkpoint” on start.
Signals for External Control We utilize Signals to provide external control and communication with the orchestration logic, which can come from humans or other services. For the AI service branch, a Signal allows for an external input such as a human in the loop approval or an automated system check to be received before the Billing Service executes the transaction. This provides a flexible mechanism for external input in an otherwise automated flow.
Temporal Internals: The Four Pillars of Temporal Services
A Temporal Cluster consists of four primary services that work in concert:
- Frontend Service: The gRPC entry point. It handles rate limiting, authentication, and routes requests to the appropriate internal services.
- History Service: The engine that “owns” workflow runs. It maintains the Mutable State (an in memory representation of a workflow’s current status) and persists the Event History (the durable log of everything that has happened).
- Matching Service: The task queue manager. It tracks pending tasks and matches them with available polling workers using in memory routing.
- Worker Service: An internal orchestrator for cluster-level background operations, such as replication and archival.
Temporal achieves horizontal scalability by distributing the workload across shards and partitions.
- History Shards: The History Service is split into a fixed number of shards (512 or 1024). Every workflow run is assigned to a shard by hashing the Workflow ID (using consistent hashing technique). Shards are not tied to specific hardware and they can be rebalanced across nodes if needed.
- The TransferQueueProcessor: Each shard maintains an internal Transfer Queue that acts as the bridge, pulling tasks from the History Shard and pushing them to the Matching Service.
- Task Queue Partitions: To prevent bottlenecks, Temporal transparently splits task queues into partitions. This partitioning is fully transparent to developers, who simply poll a queue by name while the engine handles the underlying distribution.

