

Six months after a feature ships, someone opens the file to fix a bug. There's a weird-looking branch in the code. Lowercases the email but only for some records. They git blame it. The PR description says "implements duplicate detection." The original Slack thread is gone. The engineer who wrote it left. The reviewer doesn't remember.
The bug fix takes a day. Re-deriving why the original rule existed takes a week. And in three out of ten cases, the fix quietly breaks the reason the weird-looking branch was there in the first place.
Your features remember nothing.
The asymmetry that AI made worse
The pace of generation sped up. AI agents can write a feature's worth of code in an afternoon. The pace of deciding what we mean didn't. Decisions still happen the old way: in threads, in calls, in someone's head.
So you end up with codebases full of fast-shipped features, each carrying a quiet debt: the reasoning behind it lives outside the repo, in places that decay. Slack messages roll off. Tickets get archived. People leave. The next person, human or agent, opens the file and has to guess.
Multiply that by every feature you ship for the next two years. That's the bill.
Specs are the memory layer your features need
We've been using OpenSpec, an open-source workflow for keeping specs in your repo, as the place where memory lives. The pitch is simple: every capability has a spec, every change to that capability has its own change folder, and they live in the repo next to the code.
The shape matters more than the format:
- Hierarchical, not flat. A feature has a main spec, the durable contract for how it should behave. Individual changes describe what's being added, removed, or refined, and why. When the change ships, those edits fold into the main spec. The history of decisions becomes navigable instead of folkloric.
- Co-located with the code. Same branch, same PR, same review. The spec can't drift from the code, because they ship together.
- Live during development, not before. Reality pushes back during implementation — an edge case nobody thought of when writing the HLD/PRD, a constraint that doesn't hold. The spec updates with the code, in the same PR. By the time the feature ships, the spec describes what was actually built and why.
That last one is the unlock. Most documentation lies because it was written before the work and never touched again. A live spec keeps writing itself as the work happens.
The change folder is live memory
OpenSpec keeps planning and implementation in a single artifact: a change folder that lives in the repo alongside the code.

It evolves across three stages, capturing three kinds of memory.
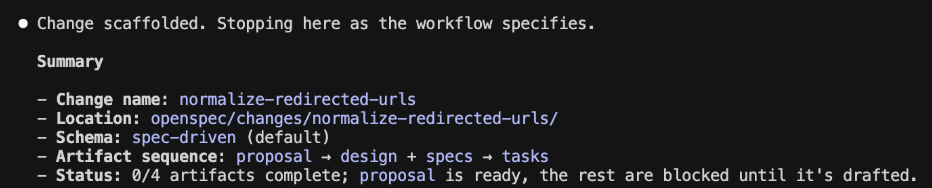
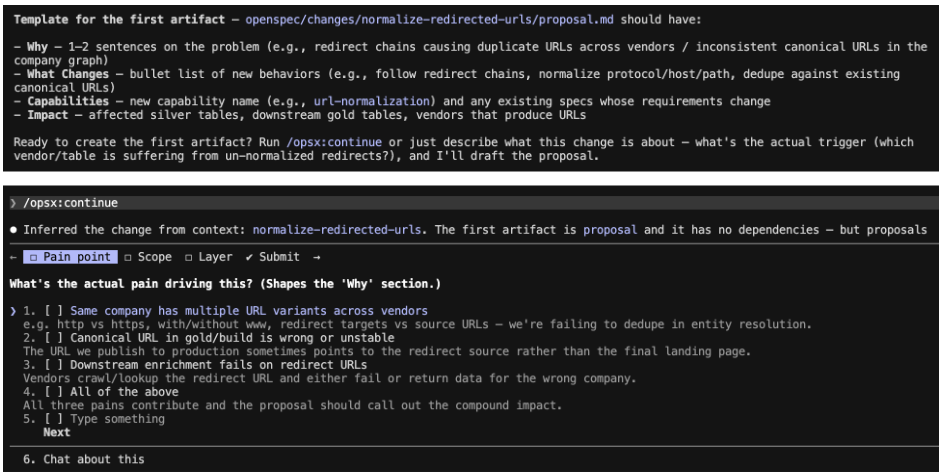
1. Planning - Memory of the decision
Before any code is written, we run a highly powerful AI planner against your draft and the existing specs. It does deep research into what you wrote and is absolutely ruthless:
- Finds conflicts and logic holes. "Draft says merge on email. Existing spec says unique (email, company_id). Which wins?"
- Flags tech gaps and anti-patterns. It spots architectural mismatches and incompatibilities with your current codebase patterns before you write a single line of code.
- Forces answers. "What if email is null?" You answer this in writing now, instead of a dev guessing at midnight.
- Cuts tasks. It breaks the work into small, reviewable steps, each tied directly to a spec change.

2. Implementation - Memory of the state
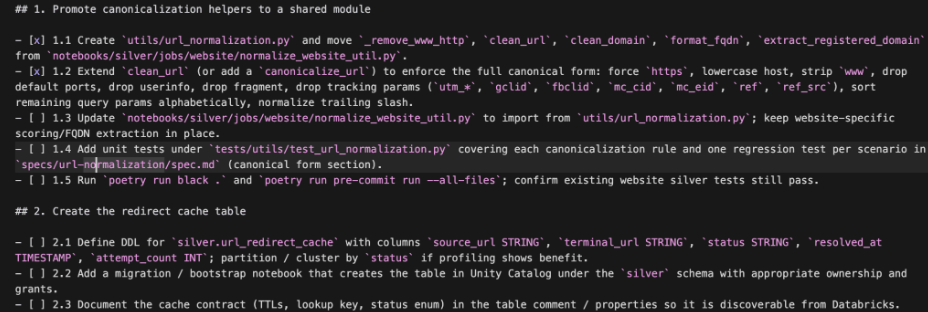
The task list isn't static. It lives in the folder and gets checked off as work ships. Anyone—a teammate, reviewer, or AI agent—can open the folder to see exactly what's done, blocked, or debated. No more "where are we on this?" Slack pings.
3. Shipping - Memory of the why
After merging, edits fold into the main spec. The change folder archives, permanently preserving the motivation, resolved conflicts, and rejected alternatives. Six months later, the engineer fixing a bug doesn't have to guess.
Ambiguities die in planning. State is visible during the build. Reasoning survives after shipping. The change folder is the continuous working memory of the feature, from conception onward.
What this means for you
Feature memory isn't a process tax. It's the move that turns shipped features from black boxes into navigable history for the next teammate, the next customer-success rep, and the next agent that touches the code.
- Treat the spec as the artifact that survives. Code is replaceable. The reasoning behind the code is not.
- Let the planner argue with you before implementation. Inner conflicts and open questions are cheap to fix in a spec. They are expensive to fix in production.
- Keep specs live during the build: Documentation written after the fact is fiction. Documentation that updates with the diff stays true.
Your codebase already remembers what you wrote. Specs are how it learns to remember what you meant.

