

A few months ago, our organization decided to migrate to Confluent (a managed Kafka and Flink service), with the assumption that all our needs could be met there. Our project quickly ran into a critical challenge called Head-of-Line (HOL) blocking.
Let me walk you through the service architecture, the problem we encountered, and why this issue arose from attempting to use Kafka topics as a message queue.
The Service Architecture
- Enriching them with context from internal data, system prompts, and much more
- Executing the enriched request against an LLM with web search tools to receive a structured response
- Further processing
- Pushing results
Initial Design: Sequential Processing
Initially, each pod would pull a message, process it, and move to the next message sequentially.
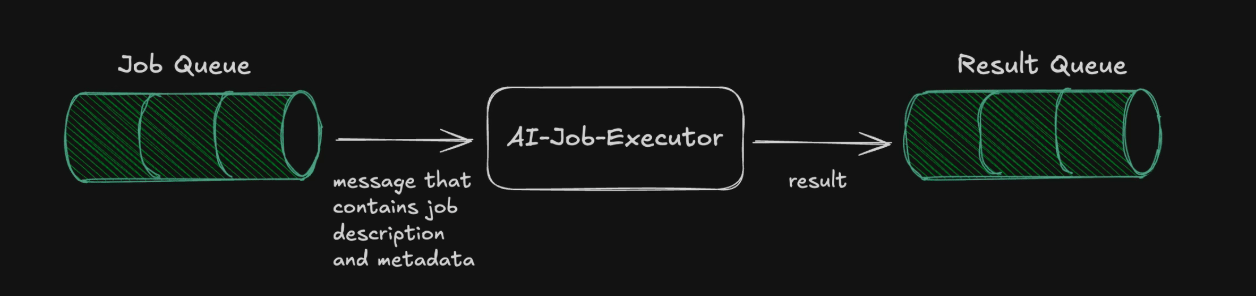
Optimization: Parallel Processing
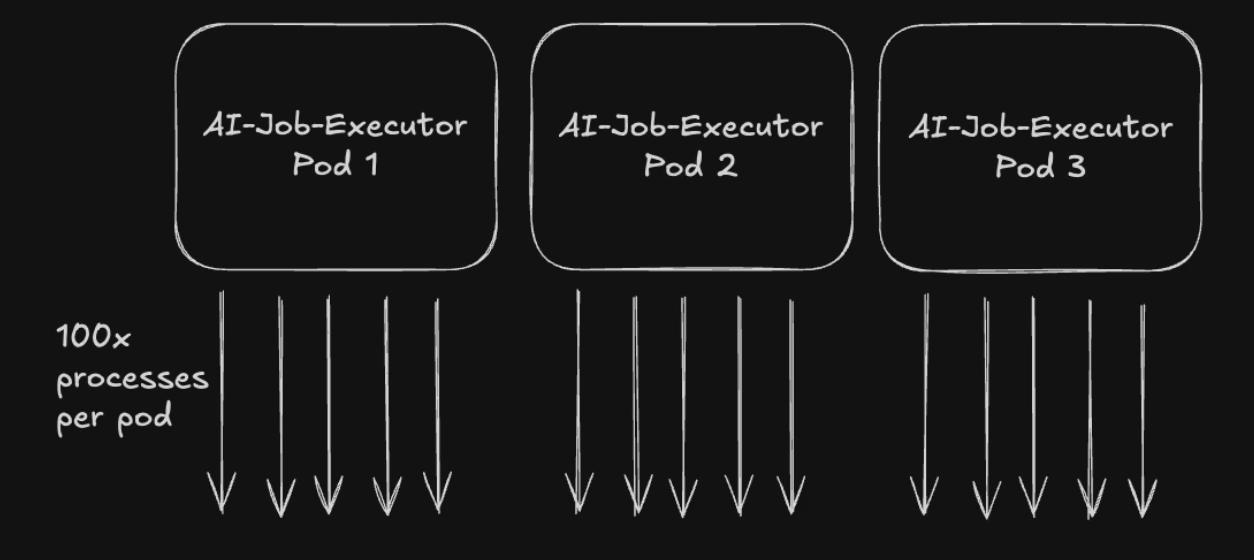
Since message processing is heavily I/O-bound-meaning most time is spent waiting for responses from internal and external services- there was significant underutilization of pod resources. After profiling resource consumption per message, I determined we could run approximately 100 concurrent processes per pod, each processing messages in parallel. With N pods running this service, we can process 100×N messages concurrently at any given moment.
The Kafka Implementation Challenge
Due to the organizational shift to Confluent, there was a hope to use Kafka instead of SQS or RabbitMQ (which was being phased out). Since there wasn’t enough time to wait for DevOps to add SQS support, I spun up two Kafka topics: x-jobs-queue for message consumption and x-jobs-results for post-processing results.
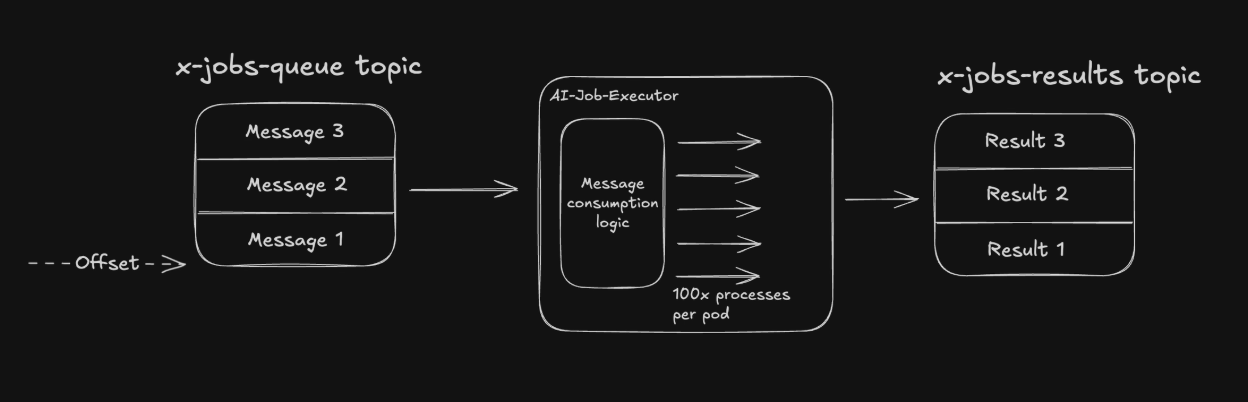
The Core Problem
The fundamental issue with this design: once a process pulls a message, the offset cannot be advanced until processing completes and the result is sent. This means the other 99 processes cannot read new messages and utilize available capacity.
Why Not Commit Offsets Immediately?
Some might suggest reading a message and immediately committing the offset. However, consider this scenario: I read Message 1, committed its offset, started processing, and then the pod crashes. When the pod restarts and checks the topic, it sees the offset now points to Message 2 and continues from there-Message 1 is lost.
What About Batch Processing?
What if we read 100 messages in a batch and commit the offset every 100 messages? In this case, we can only commit the offset when all 100 messages have successfully completed. But what if the process handling message #58 for example crashes mid-processing? Or what if one message takes 30 seconds to process while the other 99 complete in 2 seconds? The 99 processes would have to wait for the one slow process before advancing the offset to continue with new messages.
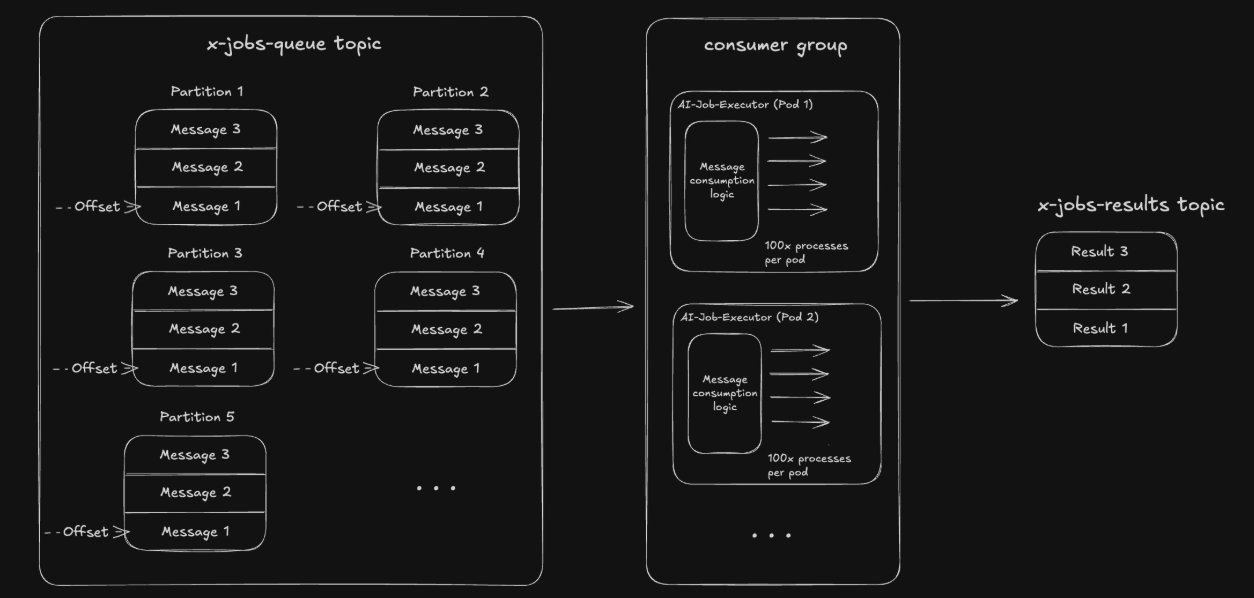
Why Not Add More Partitions?
Each partition has its own offset, so there wouldn't be dependencies between different processes, right?
Let's run through a realistic example. Suppose we partition the topic into 10,000 partitions (an excessive amount that's not recommended for performance and resource efficiency, but useful for illustration purposes).
We anticipate scale of 5,000 messages per second with processing times between 5-10 seconds each, meaning we expect 25,000-50,000 messages running concurrently. To support reasonable processing times at peak we'd need approximately ~20,000 total processes.
Given 10,000 partitions, we'd have a scenario where 10,000 processes each pull a message from a partition and block it (not committing the offset for the reasons above), but the remaining 10,000 processes would sit idle. This is called Head-of-Line blocking.
The Root Cause
The fundamental problem necessitating SQS or another traditional MQ stems from Kafka's architecture: Kafka is a log-based message broker, meaning we can only advance the offset, not acknowledge specific individual messages like in a standard MQ. Per-message acknowledgement is not supported.
The Good News: Kafka Queues
Kafka released an update about 6 months ago with a new feature called Kafka Queues. Currently, they don't recommend using it in production ("This feature is not yet recommended for use on production clusters, but it is ready for evaluation and testing").
According to last month's release notes, they introduced a new concept called Share Groups-an alternative to consumer groups. In essence, share group behavior allows multiple consumers to independently consume messages from the same topic, where each can perform per-message acknowledgement and track delivery attempts.
Note: Kafka Queues is available in early access in Apache Kafka 4.0 and will be in preview in Kafka 4.1, but it is not yet available in Confluent Cloud for production use.
Our Solution
Since Kafka Queues wasn't production-ready in Confluent Cloud, we implemented our queue using AWS SQS, which provides native per-message acknowledgement and avoids head-of-line blocking entirely. This allowed us to achieve the parallelism we needed while maintaining message reliability.
Key Takeaway: While Kafka excels at event streaming with its high-throughput, distributed architecture, it wasn't designed for traditional queue semantics with per-message acknowledgement. Understanding the distinction between log-based brokers and queue-based systems is critical when architecting distributed systems. The upcoming Kafka Queues feature (KIP-932) bridges this gap, but until it's production-ready in managed services like Confluent Cloud, purpose-built queuing solutions like SQS remain the pragmatic choice for workloads requiring independent message processing with acknowledgement guarantees.

