
It’s not uncommon at Lusha that the R&D groups get tasked with building from scratch software elements to support new features and capabilities.
On one hand, building something new can be very satisfying and a great opportunity to adopt new technologies. On the other hand, it’s a challenging job and one that requires constant reinvention and keeping our finger on the pulse of dev trends. As our traffic continues to grow, we often find that solutions that used to work for us in the past are no longer a good fit, causing us to search deeper and further.
In this post I share some of the knowledge we’ve acquired in building a scalable data collection system, read on to see what we did to build up this system.
What were we building?
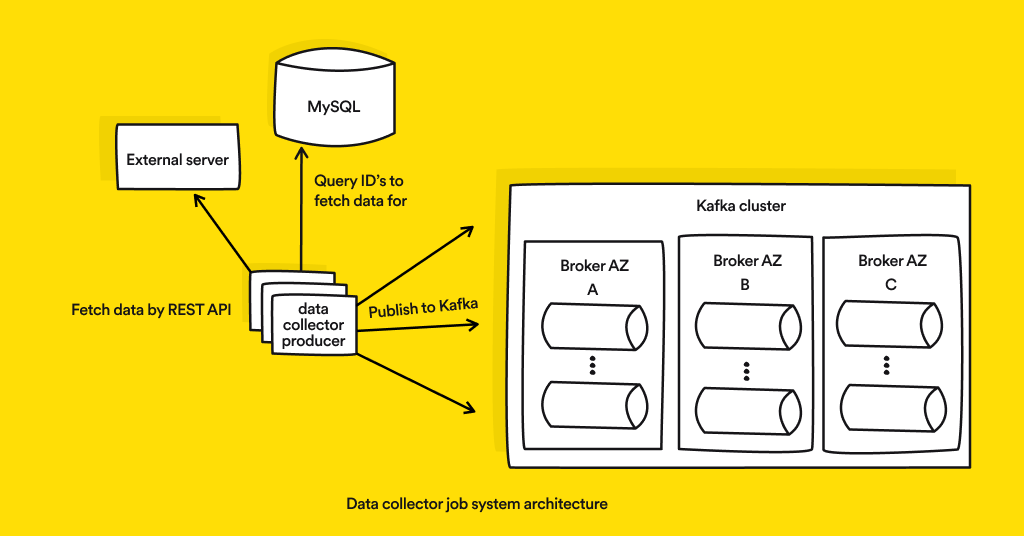
Before we dive into the ‘how’, I’ll explain the ‘what’. Our goal was to build a system that will pull data for each ID record in our databases from an external API, then process the data and publish it to a place that can be accessed by our data analysts so they can draw business insights from it.
Understanding our data
Now that I’ve explained the ‘what’, let’s talk about the ‘how’.
Lusha is a company that deals with data, first and foremost. The very first thing we do when we come to create something new is we look at the data that will go into our new system. We look at the amount of data that will need to be processed, its quality, how long it takes to pull it and create records.

We went into this project with many questions about the behavior of our system, its data collection times and its processing times. Once we had our POC, we were able to come away with a defined characteristic:
Our data collection job will run every single hour and handle 500 id records.
Now that we know what to expect from the data analysis stage, we can move to the implementation details!
Choosing our tech stack and architecture
For coding language we work with node.js. We love it because it has a large growing community and many open source libraries, and it speeds up development time as compared with to other languages. Our node.js services run inside docker containers managed by k8s (AWS EKS). For database that stores the id records we chose MySQL.
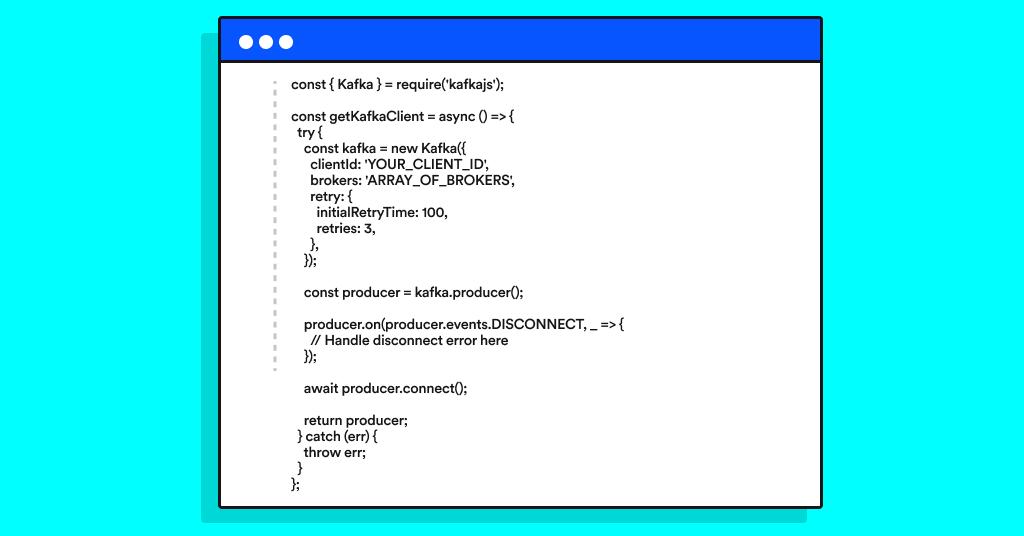
For message-bus/publisher we selected Kafka, using kafka.js node package. This has been a new and exciting addition to our R&D stack!
“Apache Kafka is an open-source distributed event streaming platform for high-performance data pipelines, streaming analytics and data integration”
Our kafka is deployed by AWS MSK (Managed Streaming for Kafka) in 3 different availability zones to achieve high availability. each availability zone (AZ) can contain up to X numbers of kafka brokers to handle the traffic. We also handle multiple topics for each different business logic data kind.
We use kafka as something between a queue to a database, because we use it as a messaging queue to publish the processed data, however since kafka also stores the messages inside, we can also relate to it as a database with retention time. This gives the consumers (the data analysts team) the freedom to consume the data in real time or not in real time by unique keys.
Last but not least, Lusha services run in containers managed by k8s. But since our data collection process can run into ‘idle time’ in which it is not processing incoming data, we opted for k8s cron-job. A cron-job is a k8s object that runs periodically according to its configuration cron time. Like the use of kafka, this too has been an implementation of new technology into our development stack.
Since we configured our data-collector job to run every hour and we already have k8s as a solution, deploying our system as cron-job instead of pod is a very simple task, and the outcome is great, because when the cron-job is not running, instead of occupying an AWS EC2 machine, the cron-job process is terminated until the next spawn.
Horizontal scale
There are cases where we want to run multiple jobs at a time, this can be easily done by configuring the cron-job yaml file to spawn multiple jobs, the challenge in this case was actually how to make each job to work on different data set, while still keeping the scale control to the infrastructure (k8s in this case).
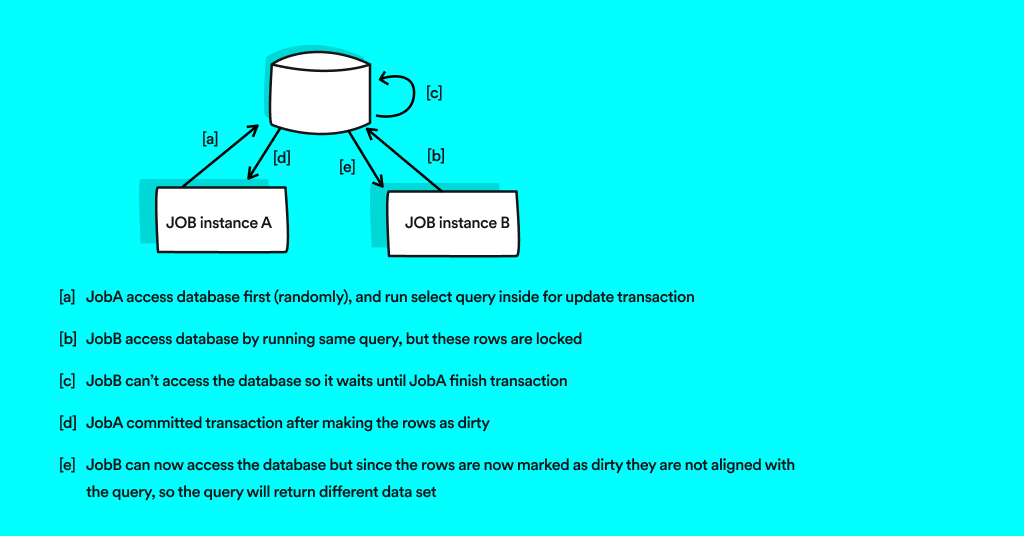
Since each job run exactly the same query to fetch the id’s from our MySQL database, we needed to find a generic solution for this problem. after some research we came up with a solution.
The first job to run the query against the table will lock only these rows as part of a transaction, then after pulling the data it will mark these rows as ‘dirty’. During this time, the database clients from other jobs go into waiting mode, and cannot access the data. When the transaction ends the rows are unlocked, the next job can access the database, but this time it will pull different data – this can be achieved using a FOR UPDATE MySQL command.
“Any lock placed with the `FOR UPDATE` will not allow other transactions to read, update or delete the row. Other transaction can read this rows only once first transaction get commit or rollback.”
Writing scalable/recoverable code
Dealing with this quantity of data requires not only an infrastructure that can uphold it, but also a a suitable code designed for big data.
Our solution has been pulling data from the external API using pagination, with each data chunk getting processed, compressed and ultimately published to kafka individually.
The fact that we are using pagination and then process the data to publish it right away, keeps the memory of our process slim, and also give us control on the data size we deliver to kafka.
In addition, in case of failures, we adapted a built in mechanism suggested by kafka.js with configurable back-off time.
Designing our code in this way safeguards from unexpected errors related to memory, and also prevents kafka from dealing with large message sizes that can slow it down.
Wrapping up
Developing something new is always an opportunity to adopt new technologies. For us, this project ushered in the use of kafka and k8s cron-jobs. I hope I was able to walk you through our process of building a scalable offline data collection job and workflow.
My one biggest insight and takeaway from this project has been the importance of analyzing the data you work with before running to implementation, because in most cases you will end up choosing better suited solutions this way.



